Awesome-model-compression-and-acceleration
Some papers I collected and deemed to be great to read, which is also what I’m about to read, raise a PR or issue in the git repository if you have any suggestion regarding the list, Thanks.
Some papers I collected and deemed to be great to read, which is also what I’m about to read, raise a PR or issue in the git repository if you have any suggestion regarding the list, Thanks.
今天突然心情有点烦躁,想着做点什么,又不知道做点什么,即使手里还有很多事情要做。我想究其原因似乎是手头事情太多了,想开头又不知道该先做哪一个,顾此失彼。
当然,每当这种情况,几乎是下意识的我就会打开 bilibili 看会动漫,或者到 youtube 上刷点无聊的东西,或者漫无目的的刷一下微博。

最近打算重新学一遍C++,趁着京东打折买了很多书,其中c++的有
一共有六本,打算在12月前按照这个顺序大致看完,这是该系列的第一篇post《essential c++》的笔记。加油~
本文为 gluon 中文教程 的笔记,虽然这个教程内容上主要是推广mxnet和gluon,但是还包含了很多其他的干货,如调参,计算图,延迟执行,符号编程,GPU模型等,所以可以作为对深度学习的一个总的复习与深入。此外,里面的一些课后题目也让自己对相关模型的理解加强了很多。总之,强烈推荐。

2017年,大概是人生中成长最快,变化最多的一年。这一年,准备了三年的出国转变成了保研,最终选择了浙大;这一年,我参加了google summer of code,写了很多开源项目;这一年,我第一次去了杭州、上海、北京、广东等地,体验了祖国的繁荣;这一年,第一次到实验室、公司去实习,体验到了工作与研究生可能经历的点点滴滴;也是这一年,体验到了人生的无限选择与可能,每一条线都可能通往不同的终点。
人生无常,但行人事,未来尤可期。

话说好久没有更新博客了,今天闲下来了,就写一篇最近要做的模型压缩的笔记好了,现在我们的需求是把现有的效果不错的模型从云端部署改成移动端离线部署,这样的话对计算的要求就很大了,所以必须要做下一步的模型压缩,我们一般需要考虑三个方面。
近年来,关于模型小型化的算法从压缩角度上可以大致分为两类:从模型权重数值角度压缩和从网络架构角度压缩。另一方面,从兼顾计算速度方面,又可以划分为:仅压缩尺寸和压缩尺寸的同时提升速度。
本文主要讨论如下几篇代表性的文章和方法,包括SqueezeNet、Deep Compression、XNorNet、Distilling、MobileNet和ShuffleNet,也可按照上述方法进行大致分类:
| Method | Compression Approach | Speed Consideration |
|---|---|---|
| SqueezeNet | architecture | NO |
| Distilling | architecture | NO |
| MobileNet | architecture | YES |
| ShuffleNet | architecture | YES |
| Deep Compression | weights | NO |
| XNorNet | weights | YES |
近来Neural style很火, 所以Deep Vision第二篇就讲一下Neural style, 下面这张图是在这个领域方面的进展. 从2015年出来最初的简单的风格重构(速度很慢, 需要实时优化), 到2016年的就出来的fast Nerual Style, 同时这篇新的论文也探讨了其在super-resolution上的应用, 可以说这个方向的进展非常快, 并且也开始向其他的方向开始展开应用.

这篇文章作为深度视觉学习的第一篇: 目标检测. 由于算法类别比较多, 所以这篇可能比较长. 主要包含

GAN和VAE作为最近非常火的生成模型, 其特点在于
颜乐存说过,2016年深度学习领域最让他兴奋技术莫过于对抗学习。对抗学习确实是解决非监督学习的一个有效方法,而无监督学习一直都是人工智能领域研究者所孜孜追求的“终极目标”之一。
Sounds simple enough, but why do we care about these networks? As Yann LeCun stated in his Quora post, the discriminator now is aware of the “internal representation of the data” because it has been trained to understand the differences between real images from the dataset and artificially created ones. Thus, it can be used as a feature extractor that you can use in a CNN. Plus, you can just create really cool artificial images that look pretty natural to me (link).

题外话: 一般来说工程上我们都是使用一些在ILSCVR上取得非常好的效果的现成的网络, 然后进行fine-tuning, 这是由于这些网络已经具有了很好的泛化能力, 对其他的问题也能很好的解决. 同时这些网络的参数很多都是公开了, 可以在其基础上训练自己的网络来解决自己的问题, 避免了从头开始训练, 也加快了训练一个模型的速度. 本文代码已放在github上.

这里准备开一个深度学习系列, 将会从最简单的autoencoder, MLP, 到CNN, RNN, LSTM, GAN等, 每种将会伴随一些经典的实现, 可能用的框架有Tensorflow和Pytorch. 本文代码已放在github上.
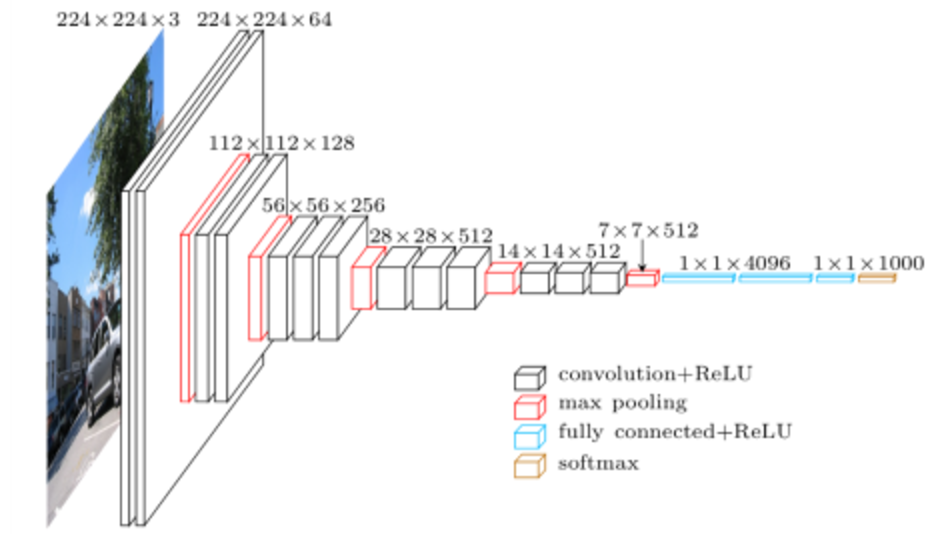
FIG. 1: MACROARCHITECTURE OF VGG16