CNN模型压缩
话说好久没有更新博客了,今天闲下来了,就写一篇最近要做的模型压缩的笔记好了,现在我们的需求是把现有的效果不错的模型从云端部署改成移动端离线部署,这样的话对计算的要求就很大了,所以必须要做下一步的模型压缩,我们一般需要考虑三个方面。
- 模型大小的压缩
- 模型速度的提升
- 模型精度的变化
近年来,关于模型小型化的算法从压缩角度上可以大致分为两类:从模型权重数值角度压缩和从网络架构角度压缩。另一方面,从兼顾计算速度方面,又可以划分为:仅压缩尺寸和压缩尺寸的同时提升速度。
本文主要讨论如下几篇代表性的文章和方法,包括SqueezeNet、Deep Compression、XNorNet、Distilling、MobileNet和ShuffleNet,也可按照上述方法进行大致分类:
| Method | Compression Approach | Speed Consideration |
|---|---|---|
| SqueezeNet | architecture | NO |
| Distilling | architecture | NO |
| MobileNet | architecture | YES |
| ShuffleNet | architecture | YES |
| Deep Compression | weights | NO |
| XNorNet | weights | YES |
1. SqueezeNet
What
SqueezeNet是F. N. Iandola,S.Han等人于2016年的论文《SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and < 0.5MB model size》中提出的一个小型化的网络模型结构,该网络能在保证不损失精度的同时,将原始AlexNet压缩至原来的510倍左右(< 0.5MB,先压缩50倍,在加上deepcompression压缩,500倍)。
How
SqueezeNet的核心指导思想是——在保证精度的同时使用最少的参数。提出了三点策略
- 将3x3卷积核替换为1x1卷积核。1个1x1卷积核的参数是3x3卷积核参数的1/9,这一改动理论上可以将模型尺寸压缩9倍。
- 减小输入到3x3卷积核的输入通道数。每个卷积层参数为$P=NC3*3$,这里减少的是C。这里层数的减少是通过squezz层。
- 尽可能的将降采样放在网络后面的层中。延迟降采样可以带来更高分辨率的特征图,从而保证精度。
基于上面3点,提出fire module,一个fire module 包含一个squeeze 卷积层(只包含1x1卷积核)和一个expand卷积层(包含1x1和3x3卷积核)。其中,squeeze层借鉴了inception的思想,利用1x1卷积核来降低输入到expand层中3x3卷积核的输入通道数。如图1所示。
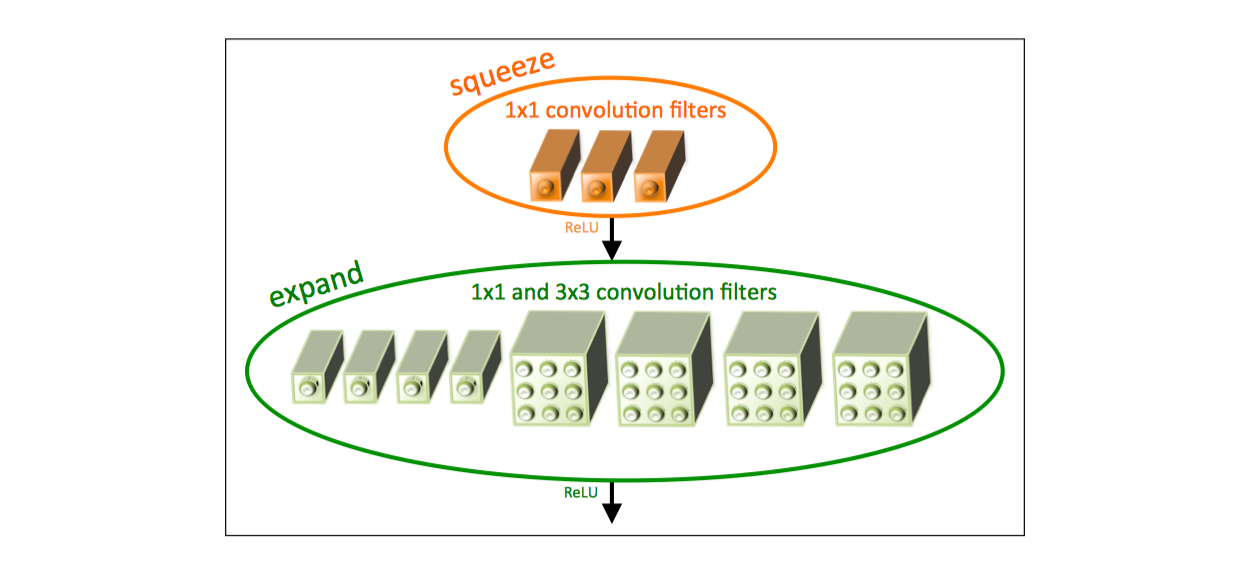
- 为了保证1x1卷积核和3x3卷积核具有相同大小的输出,3x3卷积核采用1像素的zero-padding和步长
- squeeze层和expand层均采用RELU作为激活函数
- 在fire9后采用50%的dropout
- 由于全连接层的参数数量巨大,因此借鉴NIN[11]的思想,去除了全连接层而改用global average pooling。
Result
实验结果

上表显示,相比传统的压缩方法,SqueezeNet能在保证精度不损(甚至略有提升)的情况下,达到最大的压缩率,将原始AlexNet从240MB压缩至4.8MB,而结合Deep Compression后更能达到0.47MB,完全满足了移动端的部署和低带宽网络的传输。
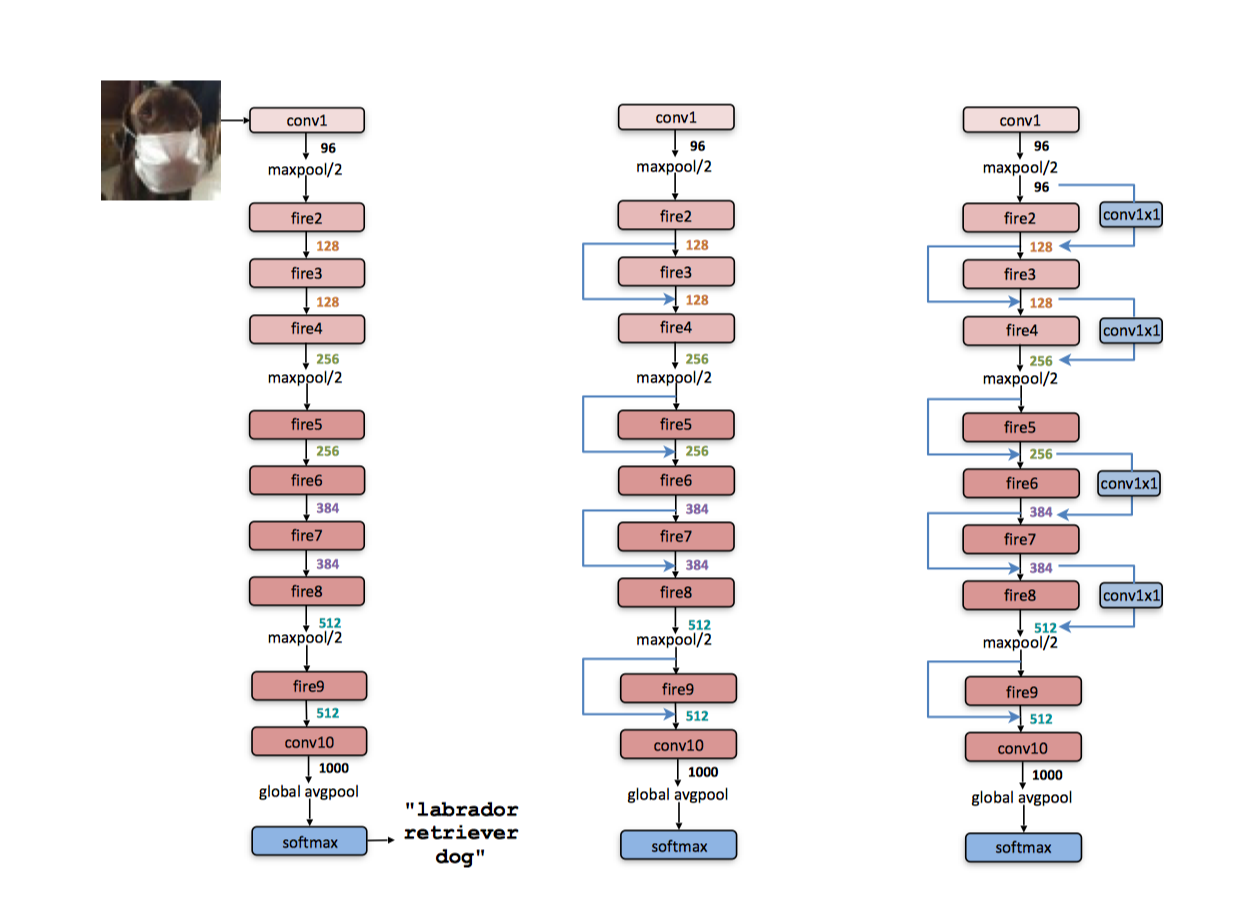
此外,作者还借鉴ResNet思想,对原始网络结构做了修改,增加了旁路分支,将分类精度提升了约3%。
尽管文章主要以压缩模型尺寸为目标,但毋庸置疑的一点是,SqueezeNet在网络结构中大量采用1x1和3x3卷积核是有利于速度的提升的,对于类似caffe这样的深度学习框架,在卷积层的前向计算中,采用1x1卷积核可避免额外的im2col操作,而直接利用gemm进行矩阵加速运算,因此对速度的优化是有一定的作用的。然而,这种提速的作用仍然是有限的,另外,SqueezeNet采用了9个fire module和两个卷积层,因此仍需要进行大量常规卷积操作,这也是影响速度进一步提升的瓶颈。
2. Deep Compression
What
Deep Compression出自S.Han 2016 ICLR的一篇论文《Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding》。该文章获得了ICLR 2016的最佳论文奖,同时也具有里程碑式的意义,引领了CNN模型小型化与加速研究方向的新狂潮,使得这一领域近两年来涌现出了大量的优秀工作与文章。
与前面的“架构压缩派”的SqueezeNet不同,Deep Compression是属于“权值压缩派”的。而两篇文章均出自S.Han团队,因此两种方法结合,双剑合璧,更是能达到登峰造极的压缩效果。这一实验结果也在上表中得到验证。
How
Deep Compression的算法流程包含三步,如图所示:

- Pruning(权值剪枝)
图3是MNIST上训练得到的LeNet conv1卷积层中的参数分布,可以看出,大部分权值集中在0处附近,对网络的贡献较小,在剪值中,将0值附近的较小的权值置0,使这些权值不被激活,从而着重训练剩下的非零权值,最终在保证网络精度不变的情况下达到压缩尺寸的目的。实验发现模型对剪枝更敏感,因此在剪值时建议逐层迭代修剪,另外每层的剪枝比例如何自动选取仍然是一个值得深入研究的课题。
2、Quantization (权值量化)
此处的权值量化基于权值聚类,将连续分布的权值离散化,从而减小需要存储的权值数量。
- 初始化聚类中心,实验证明线性初始化效果最好;
- 利用k-means算法进行聚类,将权值划分到不同的cluster中;
- 在前向计算时,每个权值由其聚类中心表示;
- 在后向计算时,统计每个cluster中的梯度和将其反传。
3、Huffman encoding(霍夫曼编码)
霍夫曼编码采用变长编码将平均编码长度减小,进一步压缩模型尺寸。
对于剪枝后的模型,由于每层大量参数为0,后续只需将非零值及其下标进行存储,文章中采用CSR(Compressed Sparse Row)来进行存储,这一步可以实现9x~13x的压缩率。存储量为$2a+n+1$
对于量化后的模型,每个权值都由其聚类中心表示(对于卷积层,聚类中心设为256个,对于全连接层,聚类中心设为32个),因此可以构造对应的码书和下标,大大减少了需要存储的数据量,此步能实现约3x的压缩率。
最后对上述压缩后的模型进一步采用变长霍夫曼编码,实现约1x的压缩率。
Result
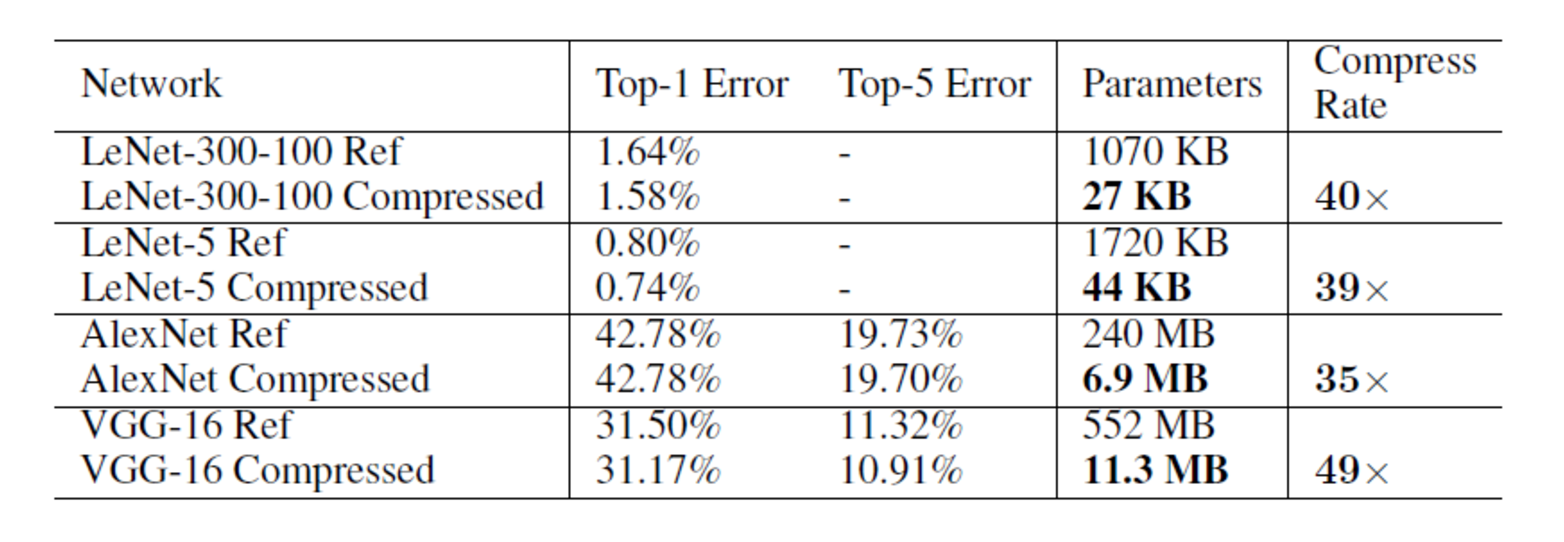
可以看出,Deep Compression的主要设计是针对网络存储尺寸的压缩,但在前向时,如果将存储模型读入展开后,并没有带来更大的速度提升。因此Song H.等人专门针对压缩后的模型设计了一套基于FPGA的硬件前向加速框架EIE,有兴趣的可以研究一下。
3. XNorNet
What
二值网络一直是模型压缩和加速领域经久不衰的研究课题之一。将原始32位浮点型的权值压缩到1比特,如何最大程度地减小性能损失就成为了研究的关键。
此篇论文主要有以下几个贡献:
- 提出了一个BWN(Binary-Weight-Network)和XNOR-Network,前者只对网络参数做二值化,带来约32x的存储压缩和2x的速度提升,而后者对网络输入和参数都做了二值化,在实现32x存储压缩的同时带了58x的速度提升;
- 提出了一个新型二值化权值的算法;
- 第一个在大规模数据集如ImageNet上提交二值化网络结果的工作;
- 无需预训练,可实现training from scratch。
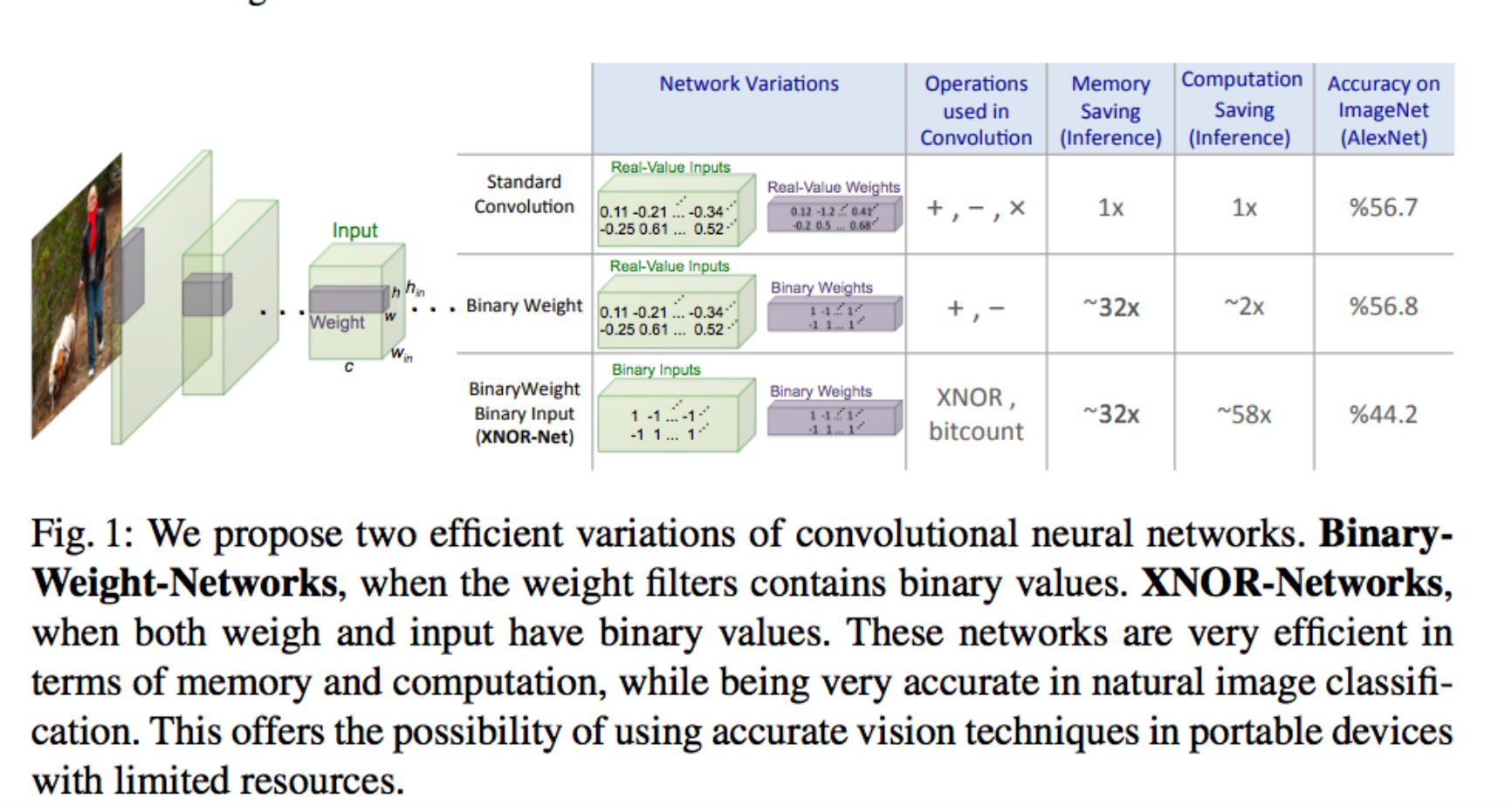
How
- BWN(Binary-Weight-Network)
二值权重网络,只对网络权重进行二值化,此时除了压缩50x倍外,由于卷积操作只有加减,因此计算速度可以加快2倍,同时大概保持原有的精度
二值化算法如下。

训练的时候分四步
- 前向计算,使用二值参数
- 后向计算,使用二值参数
- 使用梯度更新实值权重
使用实值权重更新二值参数。
XNOR-Net
同时对输入和网路权重进行二值化,此时网络只需要进行两个操作,异或以及bitcount(二值向量点积算法),此时精度大概会下降10%。

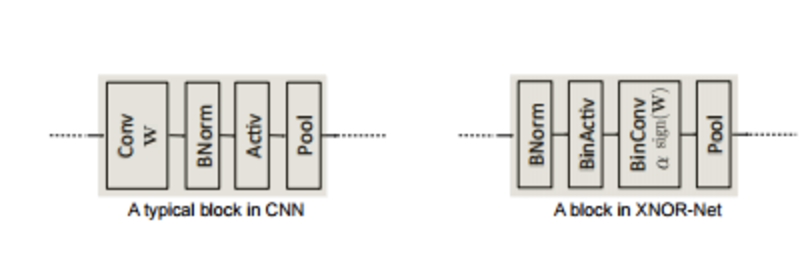
XNOR-Net中一个典型的卷积单元如图所示,与传统单元不同,各模块的顺序有了调整。为了减少二值化带来的精度损失,对输入数据首先进行BN归一化处理,BinActiv层用于对输入做二值化,接着进行二值化的卷积操作,最后进行pooling。
Result
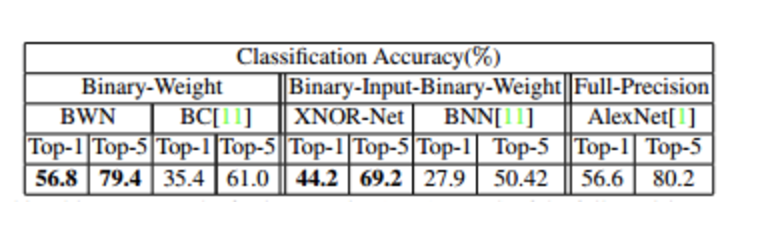
与ALexNet相比,BWN网络能够达到精度基本不变甚至略好,XNOR-Net由于对输入也做了二值化,性能稍降。
4. Distilling
What
Distilling算法是Hinton等人在论文Distilling the Knowledge in a Neural Network中提出的一种类似网络迁移的学习算法。
How
Distilling直译过来即蒸馏,其基本思想是通过一个性能好的大网络来教小网络学习,从而使得小网络能够具备跟大网络一样的性能,但蒸馏后的小网络参数规模远远小于原始大网络,从而达到压缩网络的目的。
其中,训练小模型(distilled model)的目标函数由两部分组成
1) 与大模型(cumbersome model)的softmax输出的交叉熵(cross entropy),称为软目标(soft target)。其中,softmax的计算加入了超参数温度T,用以控制输出,计算公式变为
$$q_i=\frac{exp(zi/T)}{\sum{j}exp(z_j/T)}$$
温度T越大,输出的分布越缓和,概率zi/T越小,熵越大,但若T过大,会导致较大熵引起的不确定性增加,增加了不可区分性。
至于为何要以soft target来计算损失,作者认为,在分类问题中,真值(groundtruth)是一个确定性的,即one-hot vector。以手写数字分类来说,对于一个数字3,它的label是3的概率是1,而是其他数值的概率是0,而对于soft target,它能表征label是3的概率,假如这个数字写的像5,还可以给出label是5的一定概率,从而提供更多信息,如
2)与真值(groundtruth)的交叉熵(T=1)
训练的损失为上述两项损失的加权和,通常第二项要小很多。
Result
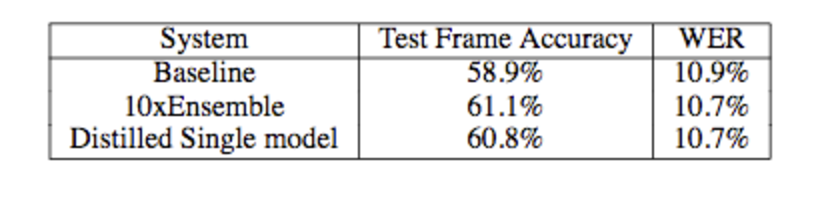
上表显示,蒸馏后的模型的精确度和单字错误率和用于产生软目标的10个模型的性能相当,小模型成功地学到了大模型的识别能力。
速度考量
Distilling的提出原先并非针对网络加速,而最终计算的效率仍然取决于蒸馏模型的计算规模,但理论上蒸馏后的小模型相对原始大模型的计算速度在一定程度上会有提升,但速度提升的比例和性能维持的权衡是一个值得研究的方向。
5. MobileNet
What
MobileNet是由Google提出的针对移动端部署的轻量级网络架构。考虑到移动端计算资源受限以及速度要求严苛,MobileNet引入了传统网络中原先采用的group思想,即限制滤波器的卷积计算只针对特定的group中的输入,从而大大降低了卷积计算量,提升了移动端前向计算的速度。
How
MobileNet借鉴factorized convolution的思想,将普通卷积操作分成两部分:
- Depthwise Convolution
每个卷积核滤波器只针对特定的输入通道进行卷积操作,如下图所示,其中M是输入通道数,DK是卷积核尺寸:
- Pointwise Convolution
总的计算缩放量就是

MobileNet的卷积单元如下图所示,每个卷积操作后都接着一个BN操作和ReLU操作。在MobileNet中,由于3x3卷积核只应用在depthwise convolution中,因此95%的计算量都集中在pointwise convolution 中的1x1卷积中。而对于caffe等采用矩阵运算GEMM实现卷积的深度学习框架,1x1卷积无需进行im2col操作,因此可以直接利用矩阵运算加速库进行快速计算,从而提升了计算效率。
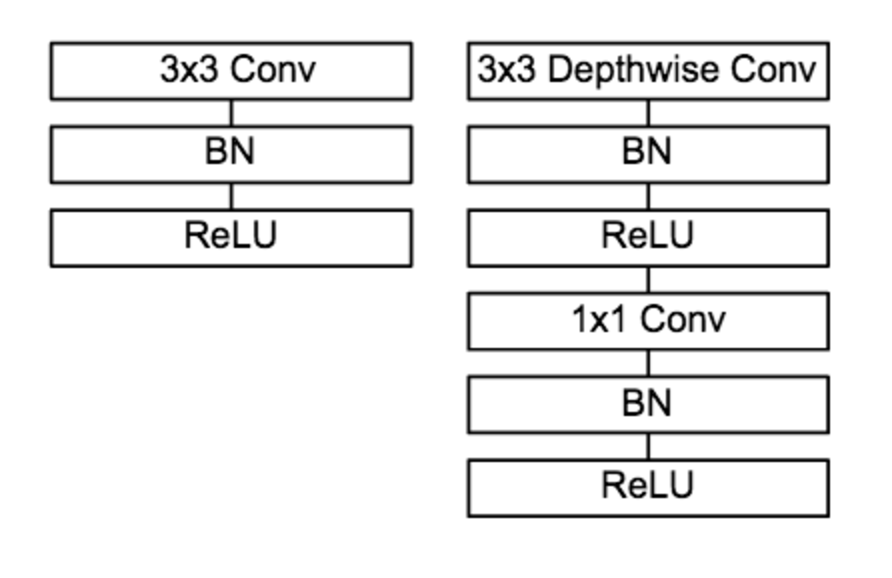
网络架构如下
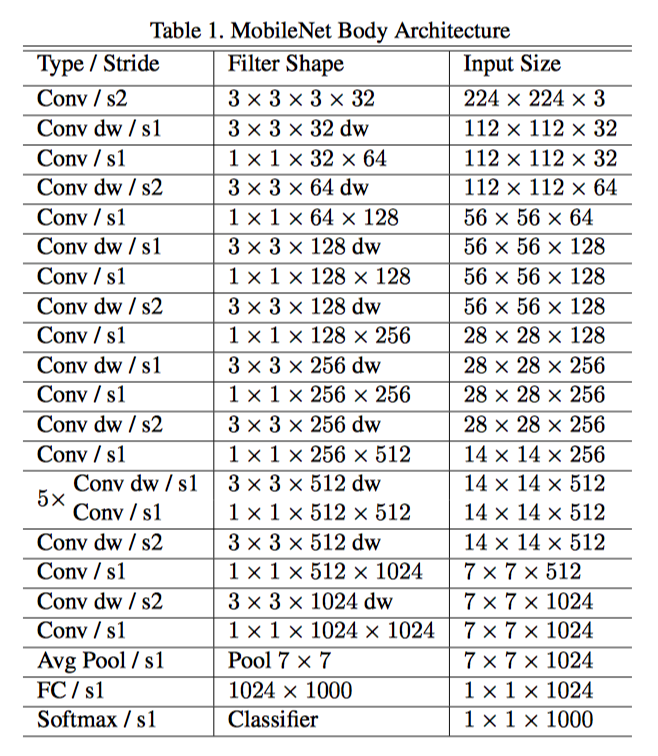
可以看到是把原来的卷积分成depthwise卷积和1x1卷积来进行计算压缩
Xception网络就是基于以上的问题发明而来。我们首先对每一个通道进行各自的卷积操作,有多少个通道就有多少个过滤器。得到新的通道feature maps之后,这时再对这批新的通道feature maps进行标准的1×1跨通道卷积操作。这种操作被称为 “DepthWise convolution” ,缩写“DW”。这种操作是相当有效的,在imagenet 1000类分类任务中已经超过了InceptionV3的表现,而且也同时减少了大量的参数,我们来算一算,假设输入通道数为3,要求输出通道数为256,两种做法:1.直接接一个3×3×256的卷积核,参数量为:3×3×3×256 = 6,9122.DW操作,分两步完成,参数量为:3×3×3 + 3×1×1×256 = 795,又把参数量降低到九分之一!因此,一个depthwise操作比标准的卷积操作降低不少的参数量,同时论文中指出这个模型得到了更好的分类效果。
Result

上表显示,MobileNet在保证精度不变的同时,能够有效地减少计算操作次数和参数量,使得在移动端实时前向计算成为可能。
6. ShuffleNet
What
ShuffleNet是Face++今年提出了一篇用于移动端前向部署的网络架构。ShuffleNet基于MobileNet的group思想,将卷积操作限制到特定的输入通道。而与之不同的是,ShuffleNet将输入的group进行打散,从而保证每个卷积核的感受野能够分散到不同group的输入中,增加了模型的学习能力。
How
在AlexNet的Group Convolution当中,特征的通道被平均分到不同组里面,最后再通过两个全连接层来融合特征,这样一来,就只能在最后时刻才融合不同组之间的特征,对模型的泛化性是相当不利的。为了解决这个问题,ShuffleNet在每一次层叠这种Group conv层前,都进行一次channel shuffle,shuffle过的通道被分配到不同组当中。进行完一次group conv之后,再一次channel shuffle,然后分到下一层组卷积当中,以此循环。
- 提出了一个类似于ResNet的BottleNeck单元
借鉴ResNet的旁路分支思想,ShuffleNet也引入了类似的网络单元。不同的是,在stride=2的单元中,用concat操作代替了add操作,用average pooling代替了1x1stride=2的卷积操作,有效地减少了计算量和参数。单元结构如图所示。

ShuffleNet Units. a) bottleneck unit [9] with depthwise convolution (DWConv) [3, 12]; b) ShuffleNet unit with pointwise group convolution (GConv) and channel shuffle; c) ShuffleNet unit with stride = 2.
提出将1x1卷积采用group操作会得到更好的分类性能
在MobileNet中提过,1x1卷积的操作占据了约95%的计算量,所以作者将1x1也更改为group卷积,使得相比MobileNet的计算量大大减少。提出了核心的shuffle操作将不同group中的通道进行打散,从而保证不同输入通道之间的信息传递。
group conv操作如下

和mobile-net主要的不同是用group-conv代替了depthwise-conv及pointwise-conv,然后用channel shuffle解决信息传递的问题。
结构如下
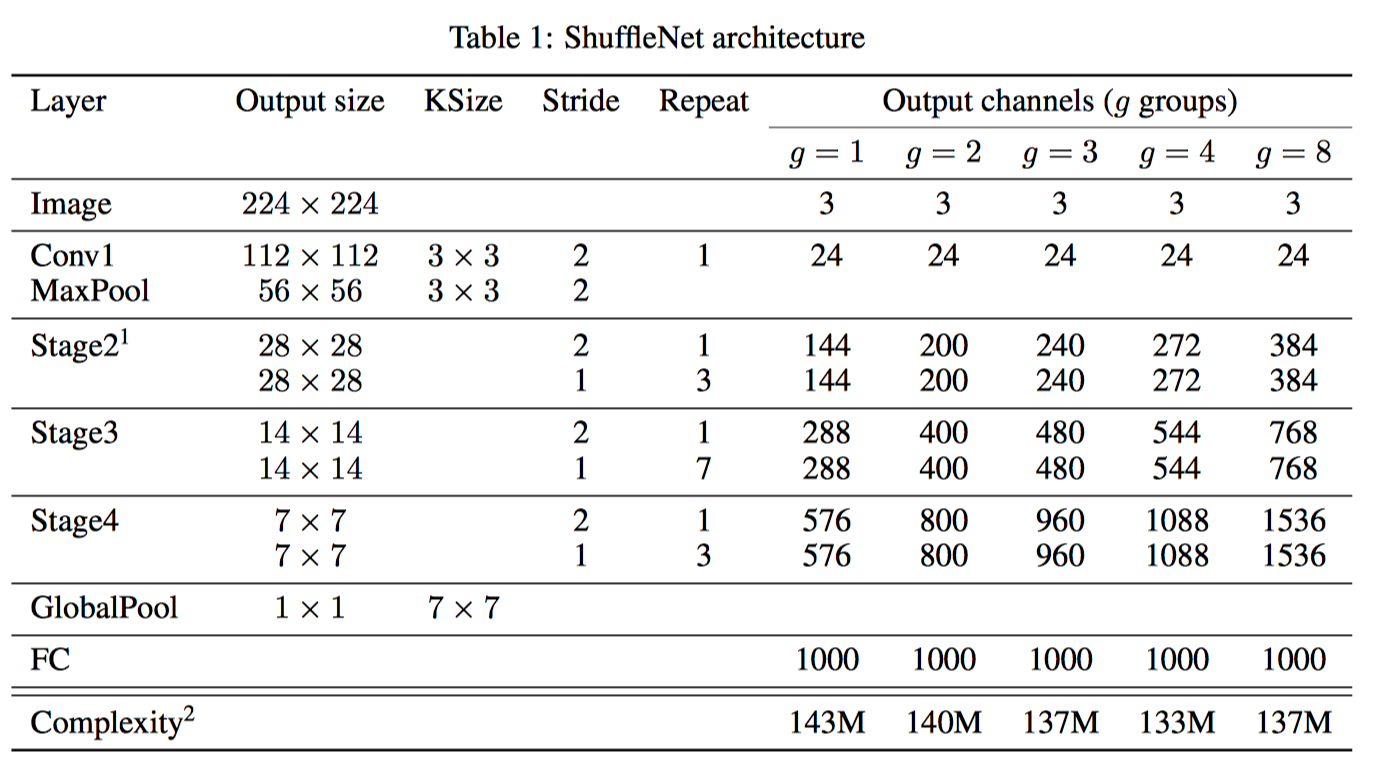
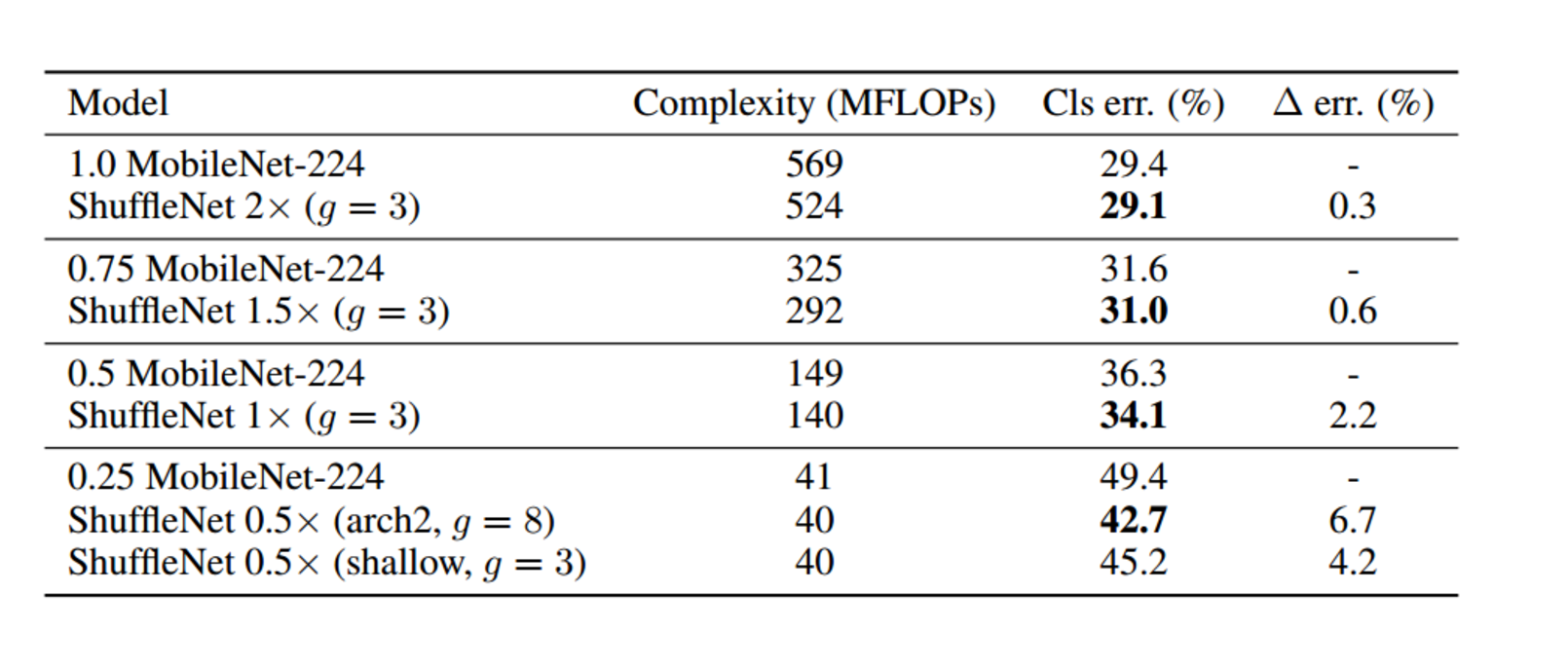
Result
如表显示,相对于MobileNet,ShuffleNet的前向计算量不仅有效地得到了减少,而且分类错误率也有明显提升,验证了网络的可行性。
作者在ARM平台上对网络效率进行了验证,鉴于内存读取和线程调度等因素,作者发现理论上4x的速度提升对应实际部署中约2.6x。作者给出了与原始AlexNet的速度对比,如下表。
