cs229机器学习笔记及代码

本文作为Ng机器学习课程的笔记, 其实开始渐渐续续的看过一些, 但是都是间断的看的, 没有系统性, 所以这次准备从头开始刷一遍, 同时包括习题.
本笔记已基本完成, PDF在此下载.
2. 线性回归
首先介绍了线性回归, 然后利用梯度下降计算了迭代过程, 之后利用梯度为0, 推出理论解, 即最小二乘法的理论解
3. 局部加权回归(LWR loess), 最小二乘法的概率解释, logistic, 感知器.
非参数模型的参数会变化
参数模型的参数不变
总结一下, LWR算法是我们遇到的第一个non-parametric(非参数)学习算法,而线性回归则是我们遇到的以一个parametric(参数)学习算法。所谓参数学习算法它有固定的明确的参数,参数一旦确定,就不会改变了,我们不需要在保留训练集中的训练样本。而非参数学习算法,每进行一次预测,就需要重新学习一组,是变化的,所以需要一直保留训练样本。也就是说,当训练集的容量较大时,非参数学习算法需要占用更多的存储空间,计算速度也较慢。有得必有失,效果好当然要牺牲一些其他的东西
需要注意的是
Loess
局部加权回归, loess需要计算gram矩阵进行计算(引入kd树), 除了原来线性回归的参数, 还添加了一个波长参数, 用来表示权重(离目标点越近的点, 权重越高, 计算公式用指数衰减函数.
$$w^{(i)}=e^{\frac{(x-x^i)^2}{(2*\sigma^2)}}$$
面试问了如何在海量数据中查找给定部分数据最相似的top200向量,向量的维度也很高. 因为之前了解过其他面蚂蚁金服的朋友,也有问到这个题目的
所以反应比较快,直接就说可以用KD树,聚类,hash,
一天之内两连面,还是问了很多机器学习算法的东西 为什么LR需要归一化或者取对数,为什么LR把特征离散化后效果更好 为什么把特征组合之后还能提升,反正这些基本都是增强了特征的表达能力,或者更容易线性可分吧还问了项目和比赛
why least-square?
根据中心极限定理, 很多独立随机变量的和趋向于正太分布, (很多因素影响误差)
$$y^{i}=\theta^{T}x^i+\epsilon^i$$
其中$\epsilon^i$由中心极限定理, 假设为高斯分布.
由此可以有
$$P(y^{i}|x^{i};\theta)=\frac{1}{\sqrt{2\pi}\sigma}e^{\frac{(\theta^Tx^i-y^i)^2}{2{\sigma^2}}}$$
那么对数据集, 我们可以写出似然函数
似然函数的意义: 在给定参数的条件下, 出现给定数据集的概率, 那么找到使得数据集出现几率最大的$\theta$, 就是极大似然估计, 计算方法是对每一个样本(sample)求出条件概率密度$P(y|x)$, 然后相乘去对数, 即对数似然函数, 然后用最优化的方法求出参数$\theta$
对似然函数取对数, 有对数似然函数, 其形式
$$L(\theta)=logl(\theta)=-mlog\sqrt{2\pi}\sigma-\frac{1}{2\sigma^2}\sum^m_{i=1}(\theta^{T}x^i-y^i)^2$$
对于$\sigma,m$, 看做常数, 就可以转换成平方和最小问题
所以, 最小二乘法的本质是极大似然估计.
logistic
对于目标值为连续值得回归问题, 用线性回归或者loess可能比较好, 但是对于离散值的分类问题, 需要引入新的方法.
引入sigmoid函数或者logistic函数
$$l(z)=\frac{1}{1+e^{-z}}$$
把$z$替换为线性模型的$\theta^{T}x$, 就有了logistic模型.
进一步求出条件概率(conditional probability)
对于二分类问题
$$P(y=1|x;\theta)=h_{\theta}(x)$$
更一般的
$$P(y|x;\theta)=(h_{\theta}(x))^y(1-h_{\theta}(x))^{1-y}$$
对数据集, 给出对数似然函数.
对于梯度推导, 先假设一个数据, 然后加个$\sum$即可.
最后利用梯度下降方法求出的递推方法和之前最小二乘的形式一样. 不同的是模型函数不同.
需要注意的是logistic本身也是训练一个超平面, 平面是$g(z)=0.5$
如下和svm的对比

线性模型都是极大似然估计!
那么最大熵就是最大熵
最大熵模型
$$I(X,Y)=H(X)+H(Y)-H(X,Y)$$
$$H(Y|X)=H(X,Y)-H(X)$$
$$H(Y|X)=H(Y)-I(X,Y)$$
其中$I(X,Y)$是互信息.
熵是随机变量不确定性的度量,不确定性越大,熵值越大;若随机变量退化成定值,熵为0。如果没有外界干扰,随机变量总是趋向于无序,在经过足够时间的稳定演化,它应该能够达到的最大程度的熵
为了准确的估计随机变量的状态,我们一般习惯性最大化熵,认为在所有可能的概率模型(分布)的集合中,熵最大的模型是最好的模型。换言之,在已知部分知识的前提下,关于未知分布最合理的推断就是符合已知知识最不确定或最随机的推断,其原则是承认已知事物(知识),且对未知事物不做任何假设,没有任何偏见。
例如,投掷一个骰子,如果问”每个面朝上的概率分别是多少”,你会说是等概率,即各点出现的概率均为1/6。因为对这个”一无所知”的色子,什么都不确定,而假定它每一个朝上概率均等则是最合理的做法。从投资的角度来看,这是风险最小的做法,而从信息论的角度讲,就是保留了最大的不确定性,也就是说让熵达到最大。
总的来说, 熵最大就是假定每一个事情发生的概率尽可能一样.(无偏假设)
实践经验和理论计算都告诉我们,在完全无约束状态下,均匀分布等价于熵最大(有约束的情况下,不一定是概率相等的均匀分布。 比如,给定均值和方差,熵最大的分布就变成了正态分布 )。
最大熵模型的本质,它要解决的问题就是计算Y在X下的的条件概率,(计算条件概率),且尽可能让这个条件熵最大
先给结果:
最大熵模型和逻辑斯蒂回归没有实质性的区别,他们都是对数线性模型
解释:
逻辑斯蒂回归是对于二分类问题的概率模型,最大熵将相同的原理推广到了多分类.
两者都是对最大熵模型(对数线性模型)的极大似然估计, 但是先验概率一个是伯努利分布, 一个是多项式分布.

损失函数
引入正则项, 使模型尽可能简单.(更好的泛化能力), 融入先知识.
根据损失函数的不同
- 平方损失, 最小二乘(极大似然)
- 对数损失, 最大熵原理(引出softmax, logstic), 都是对数线性模型.
- 合页损失(hinge loss), SVM
- 指数损失, boosting
不同的损失函数对应不同的拟合特性
规则化函数Ω(w)也有很多种选择,一般是模型复杂度的单调递增函数,模型越复杂,规则化值就越大。比如,规则化项可以是模型参数向量的范数。然而,不同的选择对参数w的约束不同,取得的效果也不同,但我们在论文中常见的都聚集在:零范数、一范数、二范数、迹范数、Frobenius范数和核范数等等。
- L0就是让0的个数尽可能大(稀疏化), 如压缩感知, 稀疏编码.
- L1范数各个元素绝对值的和(lasso,稀疏规则算子), L0范数的最优凸近似.既然 L0可以实现稀疏,为什么不用L0,而要用L1呢?个人理解一是因为L0范数很难优 化求解(NP难问题),二是L1范数是L0范数的最优凸近似,而且它比L0范数要容 易优化求解。所以大家才把目光和万千宠爱转于L1范数。

一句话总结:L1范数和L0范数可以实现稀疏,L1因具有比L0更好的优化求解特性而被广泛应用。
为什么要稀疏
- 特征选择
- 可解释性
- L2, 岭回归”(Ridge Regression), 有人也叫它“权值衰减weight decay”它的强大功效是改善机器学习里面一个非常重要的问题:过拟合。至于过拟合是什么,上面也解释了,就是模型训练时候的误差很小,但在测试的时候误差很大,也就是我们的模型复杂到可以拟合到我们的所有训练样本了,但在实际预测新的样本的时候,糟糕的一塌糊涂。通俗的讲就是应试能力很强,实际应用能力很差。
- L2范数是指向量各元素的平方和然后求平方根。我们让L2范数的规则项||W||2最小,可以使得W的每个元素都很小,都接近于0,但与L1范数不同,它不会让它等于0,而是接近于0,这里是有很大的区别的哦。而越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象。 从优化或者数值计算的角度来说,L2范数有助于处理 condition number不好的情况下矩阵求逆很困难的问题。哎,等等,这condition number是啥?我先google一下哈。
优化有两大难题,一是:局部最小值,二是:ill-condition病态问题。前者俺就不说了,大家都懂吧,我们要找的是全局最小值,如果局部最小值太多,那我们的优化算法就很容易陷入局部最小而不能自拔,这很明显不是观众愿意看到的剧情。那下面我们来聊聊ill-condition。ill-condition对应的是well-condition。那他们分别代表什么?假设我们有个方程组AX=b,我们需要求解X。如果A或者b稍微的改变,会使得X的解发生很大的改变,那么这个方程组系统就是ill-condition的,反之就是well-condition的。我们具体举个例子吧:

对于一个ill-condition的系统,我的输入稍微改变下,输出就发生很大的改变,
上面的condition number就是拿来衡量ill-condition系统的可信度的。condition number衡量的是输入发生微小变化的时候,输出会发生多大的变化。也就是系统对微小变化的敏感度。condition number值小的就是well-conditioned的,大的就是ill-conditioned的。
如果方阵A是非奇异的,那么A的conditionnumber定义为:
$$k(A)=||A|| ||A^{-1}||$$
也就是矩阵A的norm乘以它的逆的norm。所以具体的值是多少,就要看你选择的norm是什么了。如果方阵A是奇异的,那么A的condition number就是正无穷大了。实际上,每一个可逆方阵都存在一个condition number。但如果要计算它,我们需要先知道这个方阵的norm(范数)和Machine Epsilon(机器的精度)。为什么要范数?范数就相当于衡量一个矩阵的大小,我们知道矩阵是没有大小的,当上面不是要衡量一个矩阵A或者向量b变化的时候,我们的解x变化的大小吗?所以肯定得要有一个东西来度量矩阵和向量的大小吧?对了,他就是范数,表示矩阵大小或者向量长度。OK,经过比较简单的证明,对于AX=b,我们可以得到以下的结论:
对condition number来个一句话总结:conditionnumber是一个矩阵(或者它所描述的线性系统)的稳定性或者敏感度的度量,如果一个矩阵的condition number在1附近,那么它就是well-conditioned的,如果远大于1,那么它就是ill-conditioned的,如果一个系统是ill-conditioned的,它的输出结果就不要太相信了。
那么对于线性最小二乘, 引入L2范数, 解析解编程
$$w^*=(X^TX+\lambda I)X^Tb$$
另外,如果使用迭代优化的算法,condition number 太大仍然会导致问题:它会拖慢迭代的收敛速度,而规则项从优化的角度来看,实际上是将目标函数变成λ-strongly convex(λ强凸)的了。哎哟哟,这里又出现个λ强凸,啥叫λ强凸呢?
$$f(y)\geq f(x)+<\nabla f(x),y-x>+\frac{2}||y-x||^2$$
时,我们称f为λ-stronglyconvex函数,其中参数λ>0。当λ=0时退回到普通convex 函数的定义。
直观来讲,convex 性质是指函数曲线位于该点处的切线,也就是线性近似之上,而 strongly convex 则进一步要求位于该处的一个二次函数上方,也就是说要求函数不要太“平坦”而是可以保证有一定的“向上弯曲”的趋势。专业点说,就是convex 可以保证函数在任意一点都处于它的一阶泰勒函数之上,而strongly convex可以保证函数在任意一点都存在一个非常漂亮的二次下界quadratic lower bound。当然这是一个很强的假设,但是同时也是非常重要的假设。可能还不好理解,那我们画个图来形象的理解下。
- 核范数, 目的是低秩,那约束低秩只是约束rank(w)呀,和我们这节的核范数有什么关系呢?他们的关系和L0与L1的关系一样。因为rank()是非凸的,在优化问题里面很难求解,那么就需要寻找它的凸近似来近似它了。对,你没猜错,rank(w)的凸近似就是核范数||W||*。
感知器算法
本质上就是一个加上$sign$的线性回归.
利用$sign$进行强制分类
事实上, 以上模型, 都是应用的似然函数最大来估计参数, 最后利用梯度下降法求出的参数迭代更新公式形式都是一样的$direction = (\theta^{T}x-y).x=\epsilonx$.
4. 牛顿法, 指数分布族, 广义线性模型.
牛顿法, 本质上, 牛顿法是用来求根, 只用到一阶信息, 应用在优化中, 要求梯度为0的点, 那么用牛顿法来找梯度的根, 就需要用到原函数的二阶信息, 而牛顿法本质上是逼近局部(应用了泰勒展开), 与梯度下降不同的是应用到二阶信息, 用曲面去逼近.
应用牛顿法, 极大似然估计的迭代公式就变成了
$$\theta := \theta - {\alpha}\frac{f’(\theta)}{f’’(\theta)}$$
当$\theta$为向量时
$$\theta := \theta - {\alpha}H^{-1}\nabla_{\theta}L$$
优点是速度快, 迭代次数少, 缺点是需要计算$H$的逆, 比较耗时.(对于矩阵的逆一般能不求都用迭代的方法来避免, 因为时间问题, 也可以引入random walk.)
由于无法判断是极大还是极小, 利用$H$矩阵的性质即可, 一般$H$是半正定矩阵就是必要条件, 充分条件是正定矩阵和梯度为0.
指数分布族
包含
- 伯努利分布, 0-1分布.
- 多项式分布, 多个投币问题.
- 泊松分布 相当于多项式分布连续后分布, 网站访问量的计数
- gamma和exponential, 公交车到站
- beta分布, 小数建模
- dirichlet分布, 概率分布建模
- wishart分布, 协方差矩阵的分布
- 高斯分布
logistic分布的由来就是, 对0-1分类问题, 前置概率为伯努利分布, 写成指数分布族的形式, 就可以得到指数分布的自然参数和伯努利分布的参数的关系, 就是logistic函数, 也就是说我们只要求出了这个自然参数就可以求出我们需要的分类概率, 这个自然参数就是用因变量的线性变换表示的, 就可以转换成线性回归问题了.
GLM
进一步由指数分布族引出广义线性模型.
首先由伯努利分布转换成指数分布族, 我们引出logistic模型
有正太分布转换成指数分布族, 有自然参数等于均值,(注意自然参数在这里的作用, 可以认为自然参数是关于$x$的函数, 求出了这个函数关系, 我们就可以推出进一步的均值或者伯努利分布中的概率, 都是分布的参数), 而目标的均值在误差为正太分布的情况下等于因变量, 推出最小二乘模型.
总之, 自然参数与其他概率分布函数中的参数产生了联系, 从而得到不同的模型, 均为线性.
那么广义线性模型就是把指数分布族所有的成员作为线性模型的拓展. 通过各种非线性的连接函数扩大线性模型解决的问题.
GLM 3个假设
- $P(y|x;\theta)$~指数分布族
- 给定一个$x$, 我们目标函数为$h_{\theta}(x)=E[T(y)|x]$, 其中$T(y)$一般等于y
- $\eta=\theta^Tx$
将自然参数和原始概率分布中的参数相关联的函数称为正则响应函数(广义线性模型引入), 正则响应函数的反函数为正则关联函数.
对于广义线性模型, 需要决定的是条件概率分布服从什么分布(如对于线性问题, 由于引入了正太误差, 认为条件概率分布服从正太分布, 从而引入最小二乘法(其实就是极大似然估计), 即最小二乘模型), 当选择伯努利分布, 即logistic模型.
综上, 广义线性模型由不同的条件概率分布形成不同的模型, 进一步利用梯度法或者牛顿法对参数$\theta$进行求解, 其迭代方向计算形式是一样的$direction = (\theta^{T}x-y).x=\epsilonx$.
GLM推广
那么进一步对于多分类问题, 引入多项式分布(注意有k-1个参数, 所有$\theta$是一个矩阵), 进而利用softmax求分类问题
总的来说, 就是多项式分布引入softmax求解, 先线性回归求出k-1个类对应的参数, 然后线性变换后, (令第k的值为1), 进行softmax变换成概率值, 取最大即可.
进一步的, 对于二分类, 引入伯努利分布得到logistic模型, 将线性变换的结果变换成概率
对于多分类, 引入多项式分布得到softmax模型, 将线性变换的结果利用非线性正则响应函数变成各类概率.
5. 生成学习算法(EM?), 高斯判别分析(GDA), 朴素贝叶斯, 拉普拉斯平滑
更一般的, 其实对于生成模型和判别模型, 只用关心求的是联合概率分布还是条件概率, 对于判别函数形式, 我们把误差看做服从某种一种分布比如最常见的正太分布, 就可以转换成条件概率形式(即转换成概率模型), 就可以利用最小二乘模型求解. 生成模型先求联合概率分布, 比如朴素贝叶斯模型, 然后利用贝叶斯公式求后验概率, 取最大的后验概率.(即最大后验概率准则),对于判别模型(一般是极大似然准则). 总而言之, 先求因变量的联合概率分布(联合关系), 在对目标建模.
GDA 高斯判别分析
GDA是生成算法. GDA的假设是联合概率分布是多变量正太分布, 这里不像贝叶斯一样假设条件独立, 如果条件独立又是正太分布, 那么参数只有均值向量和方差向量, 但是非条件独立的GDA来说, 需要一个均值向量和一个协方差矩阵.
这样的话, 对于每一个类就可以构造出一个多变量正太分布, 只需要计算出对一个给定x的每一个类的概率密度, 参数学习使用极大似然估计. 只需要估计出不同类的均值向量, 协方差是不变的, 推导如下.


需要注意多变量高斯分布的概率密度为
$$P(x) = \frac{1}{(2{\pi})^{\frac{n}{2}}|\sum|^{\frac{1}{2}}}e^{-\frac{1}{2}(x-\mu)^T\sum^{-1}(x-\mu)}$$
这个方法可以求出联合概率密度, 进一步利用贝叶斯公式求出后验概率
注意, 这里贝叶斯公式是可以转换成logistic分布的形式.
事实上, 当联合概率分布服从指数分布族任意分布, 都可以转换成logitic模型, 也是logitic模型的充分条件, 但是不具有必要性.
由此, 推导logistic模型也就有两种方法
- 利用指数分布族, 当为伯努利分布
- 通过联合概率分布是指数分布族.
总之, 当数据变量服从多变量正太分布时, 用GDA更好, 因为GDA假设了多变量正太分布, 但是如果不服从这个分布, 则采用logistic模型更好, 因为做了更少的假设. 生成模型的另外一个好处是需要的数据比较少, 但是做出的假设比较多.
朴素贝叶斯
GPA针对自变量为连续值, 朴素贝叶斯针对自变量为离散值.(最常见的就是邮件分类)
VSM(vector space model)向量空间模型来表示文本.
对于连续量, 可以离散化用NB来求
拉普拉斯平滑
又被称为加1平滑, 用来解决0概率问题.
6. 神经网络
训练过程
- 前向传播, 计算出误差
- 反向更改参数, 利用链式法则.

注意logistic函数的偏导特性!
熵的本质是香农信息量 log(1/p) 的期望;
H(p) = E[ log(1/p) ] = ∑ p_i * log(1/p_i),是一个期望的计算,也是记录随机事件结果的平均编码长度;
为什么信息量 是 log(1/p) 呢? 因为:一个事件结果的出现概率越低,对其编码的bit长度就越长。 以期在整个随机事件的无数次重复试验中,用最少的 bit 去记录整个实验历史。 即无法压缩的表达,代表了真正的信息量。
在ML中
作用:用来评估,当前训练得到的概率分布,与真实分布有多么大的差异】 因为与相对熵只差一个 分布 P 的信息熵, 若 P 是固定的分布,与训练无关; Q 是估计的分布,应尽量等于 P。 二者一致时,交叉熵就等于 P 的熵.
交叉熵可在神经网络(机器学习)中作为损失函数,p表示真实标记的分布,q则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量p与q的相似性。交叉熵作为损失函数还有一个好处是使用sigmoid函数在梯度下降时能避免均方误差损失函数学习速率降低的问题,因为学习速率可以被输出的误差所控制。
1)信息熵:编码方案完美时,最短平均编码长度的是多少。
2)交叉熵:编码方案不一定完美时(由于对概率分布的估计不一定正确),平均编码长度的是多少。 平均编码长度 = 最短平均编码长度 + 一个增量3)相对熵:编码方案不一定完美时,平均编码长度相对于最小值的增加值。(即上面那个增量)
对于交叉熵在多分类使用softmax的时候自动变成对数似然损失.
计算时, 每一层都要扩展为原来的加一个常数, 如3,3,2. 权重网络为4X4,4X2, 最后一层已不用加
sigmoid的函数的导数为
$$f(x)(1-f(x))$$
BP神经网络只需要三个矩阵
前向计算各层输出矩阵
反向计算delta矩阵
利用两个矩阵更新权重矩阵
7. SVM
CS229 Lecture notes
包含线性和非线性, 当数据线性不可分时, 引入核技巧.
SVM问题是一个凸二次规划问题, 使用SMO, 序列最小化算法进行求解.
SVM的原理是什么?
SVM是一种二类分类模型。它的基本模型是在特征空间中寻找间隔最大化的分离超平面的线性分类器。(间隔最大是它有别于感知机)
(1)当训练样本线性可分时,通过硬间隔最大化,学习一个线性分类器,即线性可分支持向量机;
(2)当训练数据近似线性可分时,引入松弛变量,通过软间隔最大化,学习一个线性分类器,即线性支持向量机;
(3)当训练数据线性不可分时,通过使用核技巧及软间隔最大化,学习非线性支持向量机。
注:以上各SVM的数学推导应该熟悉:硬间隔最大化(几何间隔)—学习的对偶问题—软间隔最大化(引入松弛变量)—非线性支持向量机(核技巧)。
SVM为什么采用间隔最大化?
当训练数据线性可分时,存在无穷个分离超平面可以将两类数据正确分开。
感知机利用误分类最小策略,求得分离超平面,不过此时的解有无穷多个。
线性可分支持向量机利用间隔最大化求得最优分离超平面,这时,解是唯一的。另一方面,此时的分隔超平面所产生的分类结果是最鲁棒的,对未知实例的泛化能力最强。
然后应该借此阐述,几何间隔,函数间隔,及从函数间隔—>求解最小化1/2 ||w||^2 时的w和b。即线性可分支持向量机学习算法—最大间隔法的由来。
为什么要将求解SVM的原始问题转换为其对偶问题?
一、是对偶问题往往更易求解(当我们寻找约束存在时的最优点的时候,约束的存在虽然减小了需要搜寻的范围,但是却使问题变得更加复杂。为了使问题变得易于处理,我们的方法是把目标函数和约束全部融入一个新的函数,即拉格朗日函数,再通过这个函数来寻找最优点。)
二、自然引入核函数,进而推广到非线性分类问题。
为什么SVM要引入核函数?
当样本在原始空间线性不可分时,可将样本从原始空间映射到一个更高维的特征空间,使得样本在这个特征空间内线性可分。
引入映射后的对偶问题:
在学习预测中,只定义核函数K(x,y),而不是显式的定义映射函数ϕ。因为特征空间维数可能很高,甚至可能是无穷维,因此直接计算ϕ(x)·ϕ(y)是比较困难的。相反,直接计算K(x,y)比较容易(即直接在原来的低维空间中进行计算,而不需要显式地写出映射后的结果)。
核函数的定义:K(x,y)=<ϕ(x),ϕ(y)>,即在特征空间的内积等于它们在原始样本空间中通过核函数K计算的结果。
除了 SVM 之外,任何将计算表示为数据点的内积的方法,都可以使用核方法进行非线性扩展。
svm RBF核函数的具体公式?
Gauss径向基函数则是局部性强的核函数,其外推能力随着参数σ的增大而减弱。
这个核会将原始空间映射为无穷维空间。不过,如果 σ 选得很大的话,高次特征上的权重实际上衰减得非常快,所以实际上(数值上近似一下)相当于一个低维的子空间;反过来,如果 σ 选得很小,则可以将任意的数据映射为线性可分——当然,这并不一定是好事,因为随之而来的可能是非常严重的过拟合问题。不过,总的来说,通过调控参数σ ,高斯核实际上具有相当高的灵活性,也是使用最广泛的核函数之一。
为什么SVM对缺失数据敏感?
这里说的缺失数据是指缺失某些特征数据,向量数据不完整。SVM没有处理缺失值的策略(决策树有)。而SVM希望样本在特征空间中线性可分,所以特征空间的好坏对SVM的性能很重要。缺失特征数据将影响训练结果的好坏。
SVM是用的是哪个库?Sklearn/libsvm中的SVM都有什么参数可以调节?
用的是sklearn实现的。采用sklearn.svm.SVC设置的参数。本身这个函数也是基于libsvm实现的(PS: libsvm中的二次规划问题的解决算法是SMO)。
SVC函数的训练时间是随训练样本平方级增长,所以不适合超过10000的样本。
对于多分类问题,SVC采用的是one-vs-one投票机制,需要两两类别建立分类器,训练时间可能比较长。
sklearn.svm.SVC(C=1.0, kernel=’rbf’, degree=3, gamma=’auto’, coef0=0.0, shrinking=True, probability=False,tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape=None,random_state=None)
参数:
l C:C-SVC的惩罚参数C?默认值是1.0
C越大,相当于惩罚松弛变量,希望松弛变量接近0,即对误分类的惩罚增大,趋向于对训练集全分对的情况,这样对训练集测试时准确率很高,但泛化能力弱。C值小,对误分类的惩罚减小,允许容错,将他们当成噪声点,泛化能力较强。
l kernel :核函数,默认是rbf,可以是‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’
0 – 线性:u’v
1 – 多项式:(gammau’v + coef0)^degree
2 – RBF函数:exp(-gamma|u-v|^2)
3 –sigmoid:tanh(gammau’v + coef0)
l degree :多项式poly函数的维度,默认是3,选择其他核函数时会被忽略。
l gamma : ‘rbf’,‘poly’ 和‘sigmoid’的核函数参数。默认是’auto’,则会选择1/n_features
l coef0 :核函数的常数项。对于‘poly’和 ‘sigmoid’有用。
l probability :是否采用概率估计?.默认为False
l shrinking :是否采用shrinking heuristic方法,默认为true
l tol :停止训练的误差值大小,默认为1e-3
l cache_size :核函数cache缓存大小,默认为200
l class_weight :类别的权重,字典形式传递。设置第几类的参数C为weight*C(C-SVC中的C)
l verbose :允许冗余输出?
l max_iter :最大迭代次数。-1为无限制。
l decision_function_shape :‘ovo’, ‘ovr’ or None, default=None3
l random_state :数据洗牌时的种子值,int值
主要调节的参数有:C、kernel、degree、gamma、coef0。
SVM如何处理多分类问题?
一般有两种做法:一种是直接法,直接在目标函数上修改,将多个分类面的参数求解合并到一个最优化问题里面。看似简单但是计算量却非常的大。
另外一种做法是间接法:对训练器进行组合。其中比较典型的有一对一,和一对多。
一对多,就是对每个类都训练出一个分类器,由svm是二分类,所以将此而分类器的两类设定为目标类为一类,其余类为另外一类。这样针对k个类可以训练出k个分类器,当有一个新的样本来的时候,用这k个分类器来测试,那个分类器的概率高,那么这个样本就属于哪一类。这种方法效果不太好,bias比较高。
svm一对一法(one-vs-one),针对任意两个类训练出一个分类器,如果有k类,一共训练出C(2,k) 个分类器,这样当有一个新的样本要来的时候,用这C(2,k) 个分类器来测试,每当被判定属于某一类的时候,该类就加一,最后票数最多的类别被认定为该样本的类。
具体介绍
$\frac{1}{2}||w||^2$求导就是$w$, 注意这里是多元函数, 所以有这个结果.
引入核技巧的原因就是, 原来的支持向量机只能应用到线性分类问题, 即使存在噪声数据造成线性不可分, 我们可以引入软间隔来处理. 要想应用到非线性分类中, 我们就要引入核技巧, 想法就是把原来输入空间的数据通过一个非线性映射到特征空间, 使得原来输入空间的超曲面模型就对应于特征空间的超平面模型. 这样我们就可以直接在特征空间学习一个线性支持向量机, 间接学习出一个非线性分类模型.
具体做法是在把线性支持向量机对偶问题的目标函数的内积转而用核函数来求.
含义, 强对偶条件, 为什么对偶问题的解等于原问题的解, 因为SVM的原问题是一个凸二次规划, 然后SVM的前提条件就是数据线性可分, 也就是满足slater条件, 有了这两个条件就满足了强对偶条件. 那么对偶问题的解救等于原问题的解. 如果数据存在离群值使得不满足slater条件, 我们可以引入松弛变量. 如果本身模型是非线性的, 我们就要引入核技巧, 把数据映射到特征空间里使其满足slater条件, 最终满足这个强对偶条件.
(强对偶成立不一定要凸且slater, 是一个充分条件, 当为凸函数, KKT成为充要条件, 换句话说,如果primal problem是一个凸优化问题,且存在$x˜$和 $(λ˜,ν˜)$ 满足 KKT 条件,那么它们分别是primal problem和dual problem 的极值点并且strong duality成立.) 这里注意逻辑, 先满足slater条件和凸函数使得原问题和对偶问题的解一样, 在由充要条件推得满足KKT条件(求出$\alpha$后用来求$w,b$.
强对偶成立 -> 满足KKT条件(其一个性质, 只要满足强对偶都满足KKT, 不一定要凸或者slater), 分为三个部分.(一般我们对凸优化(目标函数和不等式约束函数是凸函数, 等式约束是仿射函数)使用KKT条件, 其满足
- 约束
- 梯度等于0(因为原问题的极值的梯度是等于0的)
- 约束不等式为0(因为p=d)
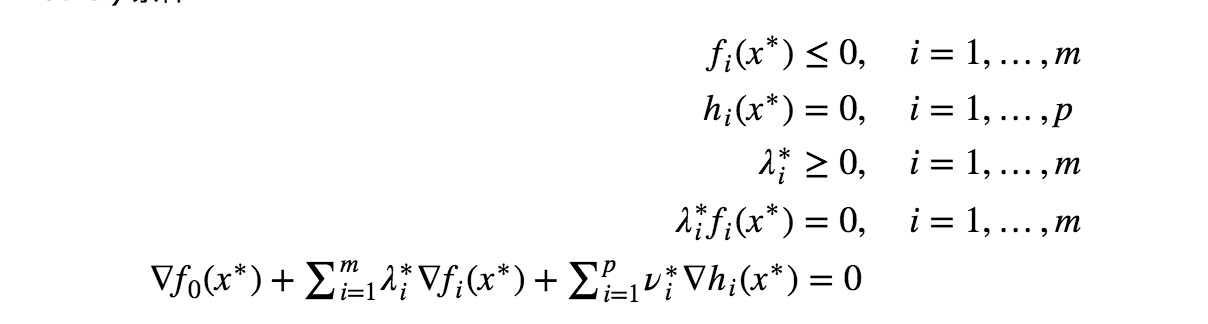
然后剩下的, 就是求解对偶问题了, 由于是凸二次规划问题, 一般用序列最小化算法计算.(这是一种启发式算法)
至于为什么要引入对偶
- 计算方便
- 目标函数表示成内积形式, 就可以引入核技巧, 使得能够处理非线性问题.
总的来说,一个优化问题,通过求出它的 dual problem ,在只有 weak duality 成立的情况下,我们至少可以得到原始问题的一个下界。而如果 strong duality 成立,则可以直接求解 dual problem 来解决原始问题,就如同经典的 SVM 的求解过程一样。有可能 dual problem 比 primal problem 更容易求解,或者 dual problem 有一些优良的结构(例如 SVM 中通过 dual problem 我们可以将问题表示成数据的内积形式从而使得 kernel trick 的应用成为可能)。此外,还有一些情况会同时求解 dual 和 primal problem ,比如在迭代求解的过程中,通过判断 duality gap 的大小,可以得出一个有效的迭代停止条件。
支持向量机的对偶目标函数, 求解需要
- 拉普拉斯算子
- 数据$X$
- target $y$
SMO(序列最小化算法)

http://www.cnblogs.com/coder2012/p/4589963.html
10. 学习理论
泛化误差上界
泛化误差包括偏差和方差.
VC维和模型选择
VC是模型集合无穷大的分析, 即一致性收敛定理.
模型选择包括
- 交叉验证(用来选择模型参数)
- 特征选择(feature selection)
这些都是模型的一些需要固定的常数(前者是真正的常数, 后者是需要压缩的特征)
VC维
首先, 对于一个复杂度的模型, 至少需要与其同等规模的样本来进行训练.(同一数量级的样本)
模型复杂度定义
- 对模型集合h可以分散数据集, 当且仅当对数据集的任何一种组合, 模型集合内都有某种假设, 将其线性分开.
在二维平面下, 对于直线集合, 它能分散的点最大数目为3, 从而又VC维.
- 对一个模型集合来说, 它的VC维, 记为VC(H), 是其能分散的最大集合的大小.

结论为, 当一个模型集合的VC维有限时, 随着样本数目增大, 训练误差和泛化误差将会一致收敛.
一般情况下, VC维和模型的参数数目线性相关, 因此, 训练模型需要的样本数和参数呈线性相关, 更一般的, 和VC维在同一数量级.
对于SVM, 虽然映射到了高纬空间, 但是有最大间隔分类器的假设, 对于最大间隔分类器来说, VC维不依赖X的维度, 对于最大间隔为$y$的分类器, 在半径内的数据点数目设为k, VC维服从如下公式:
$$VC(H)<=[\frac{k^2}{y}]+1$$
而SVM会自动寻找一个具有较小VC维的假设类, 降低了VC维, 使得数据更加充分, 提高了模型效果(虽然数据没变, 但是降低了模型VC维, 使数据更加充分!, 这条逻辑要记住, 在数据不够的情况下, 降低模型的复杂度, 会使得数据更加充分, 因为复杂度越高, 需要更多的数据使得训练误差收敛泛化误差!)
ERM(经验风险最小)
SVM和logistic作为凸近似. 使用极大似然估计.
模型选择
- 保留交叉验证,(hold-out) 7/3分, 用来模型选择. 选择测试误差最小的模型.
- k-fold, 平分k分, (最常用10), 这样就可以算10次, 然后取平均, 看最小的哪一个.
- 极端情况(leave-one-out)留一
特征选择
当特征数目远大与样本数目, 会拟合, (数据太少), 意义在于降低VC维, (数据少的时候降低模型VC维, 使得原来的样本数目变得充分, 从而得到更有效的模型).
- 前向选择方法. 用来直接从特征选取子集使用.(启发式方法), 不然有$2^n$种可能.wrapper model feature selection(每次都要进行训练和评测).原理是从0开始, 一步一步选精度上升最高的模型, 直到模型精度不在上升.
- 后向选择方法, 每次剔除精度影响最不大的特征.
这两个方法的计算量都比较大.
- 过滤法.相比前者计算量小的多
利用特征评分, 即相关性, 一种方法是利用互信息(MI, mutual information).
$$MI(x_i,y)=\sum_{x_i}\sum_yp(x_i,y)log\frac{p(x_i,y)}{p(x_)p(y)}$$
就是互熵, 这些概率可以利用训练集中得到估计值.
当然也可以表示为KL距离形式, 相对熵.
$$MI(x_i,y)=KL(p(x_i,y)||p(x_i)p(y))$$
KL距离用来衡量分布之间的差异. 如果两者相互独立, KL距离是0, 如果关联越大, KL距离越大.
使用这个就可以对每一个特征进行评分, 至于到底选择多少个, 可以用交叉验证.
一个例子就是对于文本分类, 特征数也就是词语数目非常大, 多于样本数目, 这样就需要进行特征选择.
总的来说, 特征数目降低可以有
- 选择(前后向选择)
- 过滤(利用相关性, 互信息)
- 变换(利用PCA, ICA, SVD等)
贝叶斯统计, 正则化, 在线学习,
贝叶斯和频率学派的区别在于后者认为参数值是固定的, 但是用统计学方法可以估计出参数的值, 但是贝叶斯直接认为参数是一个随机变量, 服从某个先验分布.$\theta\in p(\theta)$, 极大似然估计就是概率派, 认为参数是一个定值.由贝叶斯引出最大后验估计.
MLE与MAP.
MLE为
$$\theta_{ML}=arg{max}_\theta\prod_{i=1}{m}p(y^i|x^i;\theta)$$
$$\theta_{MAP}=arg{max}_\theta (\prod_{i=1}{m}p(y^i|x^i;\theta))p(\theta)$$
最主要的区别在于添加了先验概率$p(\theta)$, 先验修正下的最大似然估计!.
注意$;$表示后面的变量是未知值, $,$表示联合分布.
一般采用正太分布(未知情况)作为先验分布. 使用MAP相比MLE降低过拟合的概率.
最小二乘的概率解释就是最小二乘, (假设误差服从正太分布)
在线学习
样本是逐步到来的, 不是一次性拥有, 逐步更新参数
感知器算法
对于不能分类的点, 更新参数公式为
$$\theta := \theta + yx$$
ML经验
- 算法诊断(diagnostics for debugging learning algorithm)
- 误差分析(error analysis)
- 销蚀分析(ablative analysis)
- 过早优化(premature)
算法效果不好时, 先分析, 后采取对应的方法, 不要直接就用.
- 方差/偏差分析.是高方差还是高偏差.高方差是训练误差小, 泛化误差大, 高偏差是训练误差和泛华误差接近, 都很大. 看解决方案是解决方差还是偏差, 多数据只能解决高方差问题, 少特征也是解决高方差问题. 更多的特征和更好的特征可以增加复杂度->提高拟合度->解决高偏差, 一般看是会增加复杂度还是减少复杂度就OK, 增加数据可以降低模型复杂度.
- 弄清楚有没有错误风险, 不同错误的风险可能不同, 目标函数也有区别. 对不同的错误率进行加权, 弄清楚是不是优化算法的问题.
如, 对于一个自动驾驶程序
- 建立模拟器
- 选择损失函数J
- 使用RL(增强学习)对损失函数优化, 输出参数$\theta_{RL}$
这时候就要注意模拟器不一定可行, 与现实可能有差别, 如果出现不好的情况, 可能是算法没有收敛(选择优化算法), 也可能是现实问题(改进传感器等)
一个系统最开始的一定是数据采集和预处理, 后面是分类算法. 构建特征, (深入分析), 也可以慢慢分析, 慢慢改进.
在做研究时, 在确定有效的时候不要花太多精力, 要花时间到关键问题上!..
1/3的时间花在设计, 分析上是可以接受的
12. 无监督学习
kmeans
一般的聚类算法(非监督算法)有k-means, k-中值, 谱聚类, 半监督有label-propagation.
GMM
EM算法
基于Jensen不等式
- HMM的BW算法
- kmeans
实际上都是一种方法, 估计参数, 求出相关函数(E), 最大化(M), 直到参数收敛, 基于jensen不等式, $Q(\theta,\hat{\theta})$为原函数的下界, 对原函数进行近似求解.
13. PCA
思想是将n维特征映射到k维正交特征上, 从而消去冗余信息.
步骤如下
- 归一化.
- 求协方差矩阵
- 求协方差矩阵的特征值和特征向量
理解.
根据最大方差, 信号处理中认为信号具有大的方差, 而噪声具有较小的方差, 信噪比就是信号和噪声的方差比, 越大越好. 那么这映射的结果就是在k维上数据有最大的方差.
而一个点$x$在直线$u$上映射后离原点的距离为$x^Tu$, 而映射后数据的均值仍然是0, 那么要方差最大, 就有总方差.
$$\frac{1}{m}\sum_i({x^i}^Tu)^2=\frac{1}{m}\sum_i(u^Tx^i{x^i}^Tu)=u^T(\frac{1}{m}\sum_ix^i{x^i}^T)u=u^T{\Sigma}u=\lambda$$
进一步
$${\lambda}u=uu^T{\Sigma}u={\Sigma}u$$
可以看到最佳投影的直线就是$\lambda$最大的时候对应的特征向量. 剩下的可以依次类推.
注意PCA的缺点在于高斯分布假设, 当数据不服从高斯分布的时候方差最大的方向不一定是最优主优方向, 此时可以用ICA. 另外一个缺点是无监督的, 如果存在一些标注信息, 不能好好利用. 可以引入kernel-PCA, 从而利用先验信息, 先对数据进行预处理.
中心极限定理告诉我们:大量独立同分布随机变量之和满足高斯分布。
14. ICA
算法
- 归一化
- 漂白, 使得$x$的协方差矩阵为$I$, 变换为$\hat{x}=ED^{-\frac{1}{2}}E^Tx$, 对$x^Tx=EDE^T$得到$E,D$, 漂白是为了让各变量之间相互独立.
PCA和ICA的区别一个在用来还原信号(因为信号不总是高斯分布的, 类似高斯混合模型), 一个适合用来降维.
15. LDA
对于二分类, 目标函数是
$$J(w)=\frac{w^TS_Bw}{w^TS_ww}$$
其中$S{wi}=\sum{x\in{w_i}}(x-\mu_i)(x-\mui)^T$, $S{B}=(\mu_1-\mu_2)(\mu_1-\mu_2)^T$
对于多分布不同的只是$S_B$
$$S_B=\sum_i(\mu_i-\mu)(\mu_i-\mu)^T$$
利用拉格朗日对偶定理同样可以转换成广义特征值求解问题.
因为$S_wS_B^T$不一定是对称矩阵, 因此几个特征向量之间不一定正交.
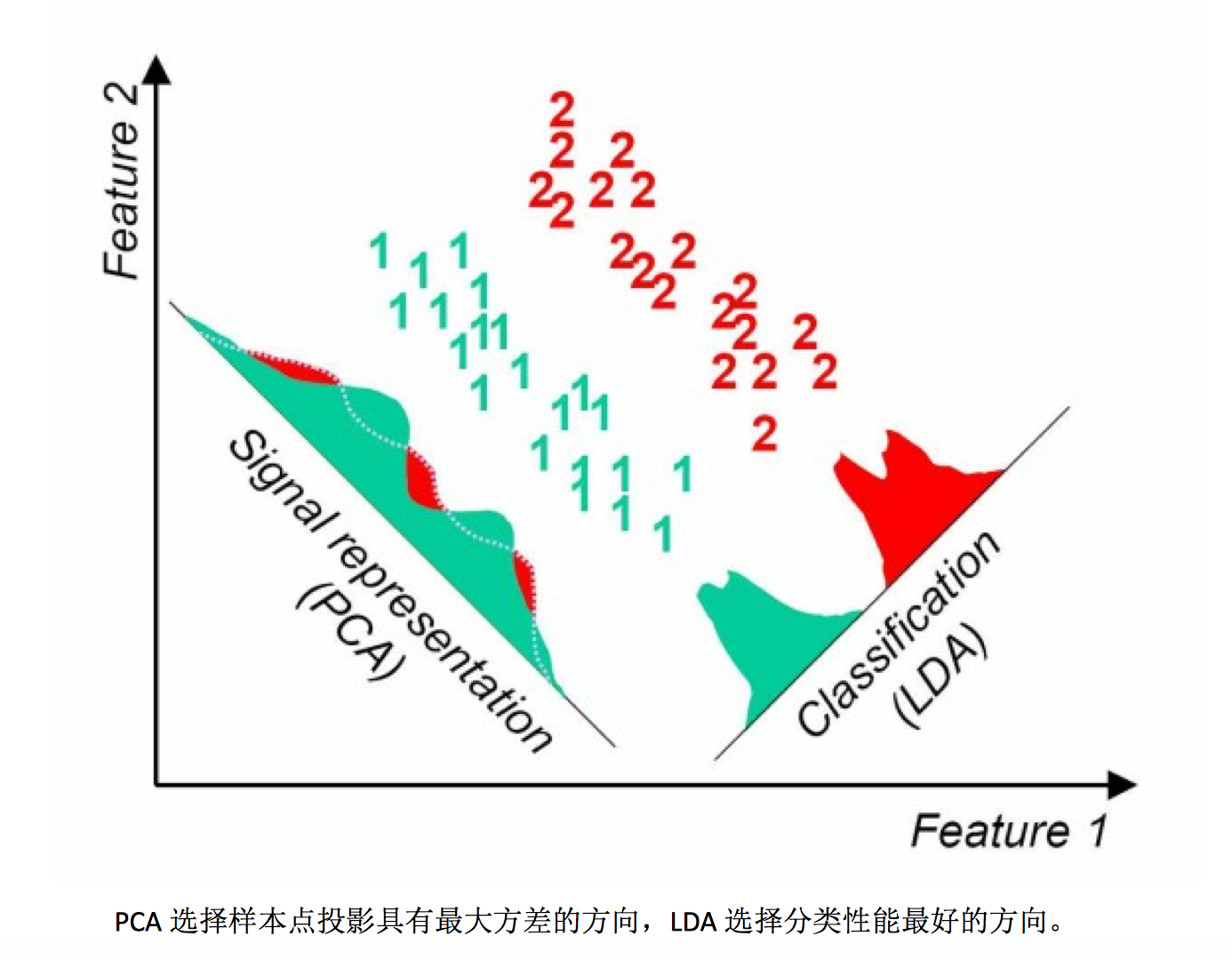
PCA和LDA的不同在于,PCA选择方差最大的方向投影, LDA选择分类性能最好的方向投影.
16. 因子分析
因子分析与回归分析不同,因子分析中的因子是一个比较抽象的概念,而回归因子有 非常明确的实际意义;
主成分分析分析与因子分析也有不同,主成分分析仅仅是变量变换,而因子分析需要 构造因子模型。
主成分分析:原始变量的线性组合表示新的综合变量,即主成分; 因子分析:潜在的假想变量和随机影响变量的线性组合表示原始变量。
cs229作业
第一次作业. 线性回归
最重要的公式, 注意黑塞矩阵不是梯度的梯度, 是梯度的每一个量分别的梯度.
向量求导和矩阵求导
注意二次型优化问题, 如果要找到最优方向, 那么令$||x||^2=1$, 我们优化
$$x^TAx$$
对偶问题是
$$L(\lambda,x)=x^TAx-{\lambda}(x^Tx-1)$$
求导
$$\frac{ {\partial}L(\lambda,x)}{ {\partial}x}=2Ax-2 \lambda x=0$$
就变成了特征值问题, 注意
$$x^Tx, b^Tx$$
的区别, 这两者的导数不一样!. 注意上面这个二次规划优化问题和瑞利商问题其实是一样的!.
$${\nabla}_xx^TAx=2Ax$$
$${\nabla}_x^2x^TAx=2A$$
$$\frac{\partial y^Tx}{ {\partial}x}=y$$
$$\frac{ {\partial} x^TAx}{\partial x}=(A+A^T)x$$
主要是对房屋价格的一个最小二乘线性回归, 我们有
$$L(\theta)=\frac{1}{2}(X\theta-y)^T(X\theta-y)$$
所以
$$L’(\theta)= 2X^T(X\theta-y)$$
不如这样计算
$$L’(\theta)=2\nabla_{\theta}(A\theta)(A\theta-b)=2*A^T(A\theta-b)$$
所以有迭代公式
$$\theta=\theta’-{\alpha} L’(\theta)=\theta’-\alpha X(X\theta’-y)$$
直到收敛或者超过迭代次数即可, 计算前注意要进行归一化.
理论解是
$$\theta=(X^TX)^{-1}X^Ty$$
这个解和梯度下降求的一样, 但是不同的是理论解需要求逆计算速度慢. 最小二乘分为线性最小二乘和非线性, 线性有理论解, 可以直接由公式推得, 同时注意过定时是无解的, 只能求最小二乘解(也就是上面的理论解), 对于欠定的, 有无数个解, 我们可以求最小范数解, 更一般的, 我们只需要求伪逆, 自动对应最小范数解和最小二乘解(求取可以用SVD分解后对对角矩阵求逆!).
但是非线性不能, 需要用LM方法迭代计算(实际上就是牛顿法), 和线性最小二乘不同的是$X$替换成了雅克比矩阵$J(x)$, 给定了初始值, 进行迭代即可(更新$J(x)$). 注意gram矩阵的计算就是$X^TX$, 这个矩阵由于不一定可逆和正定, 所以引入LM来矫正.
调参数可以log型调, 0.01, 0.03, 0.1, 0.3
第二次作业. logistic 回归
csvread可以用来读取txt, 用,间隔!


一个最需要注意的是
$$logistic(x)=\frac{1}{1+e^{-x}}$$
$$\frac{ {\partial} logistic(x)}{ {\partial}x}=logistic(x)*(1-logistic(x))$$
并且logistic模型的不再是最小二乘, 用的是最大似然, 所以目标函数不一样,为
$$J(\theta)=\sum_{i=1}^m(-y_i\theta^Tx_i+ln(1+e^{\theta^Tx_i}))$$
那么一阶导数和二阶导数为
$${\nabla}_{\theta}J(\theta)=X^T(logistic(X^T\theta)-y)$$
$${\nabla}^2J(\theta)=\frac{ {\partial}J(\theta)}{ {\partial}\theta{\theta}^T}=X^TXlogistic(X^T\theta)(1-logistic(X^T\theta))$$
同理, 对线性回归
$$\nabla^2 J(\theta)=\nabla_{\theta^T} X^T(X\theta-y)=X^TX$$
那么对于非线性项, 我们需要扩展特征, 使得回归变成非线性, 之后加入正则项, 求导后实际上就是$\lambda\theta$, 这里$\lambda$是自己设置的, 对于较大的$\lambda$, 我们会使得模型过于简单, 太小的则会使模型过于复杂, 注意trade-off.
第三次作业-多类logistic, 神经网络
向量化的logistic回归为
$$J(\theta)=\frac{1}{m}{\sum}_{i=1}^n-y_ilog(sigmoid((x_i^T\theta))-(1-y_i)log(1-sigmoid(x_i^T\theta))$$
求导
$$\nabla J(\theta) = \frac{1}{m}X^T(h(X^T\theta)-y)$$
同时注意正则化对bias项是不进行加和的, 所以在计算的时候要注意去掉$\theta$的bias项求$\theta^T\theta$
首先是oneVsAll, 对于多个类, 我们只需要对每个类都求一个$\theta$, 这里$\theta$就变成了矩阵, 对每一个类进行单独训练, 实际上就是对每一个进行二分类logistic回归, 用$J(\theta)$就可以表达, 用一个for对一个进行训练就可以了, 但是logstic回归是线性的.
然后是一个前向神经网络, 给了参数, 只用用矩阵前向计算即可.
第四次作业- 反向传播
主要讲了一下反向传播初始参数设置
$$[-\epsilon_{init},\epsilon_{init}]$$
其中
$$\epsilon_{init}=\frac{\sqrt{6}}{\sqrt{L_{in}+L_{out}}}$$, 其中$L$代表层数.
如
$$\frac{\sqrt{6}}{\sqrt{400+25}}=0.118=0.12$$
反向传播的主要想法是链式法则, 计算时利用动态规划的思想, 我们保留误差项$\delta$.
在前向传播的时候保存$z,a$, 其中$z$有$n-1$层, $a$有n层.
反向传播时计算误差项
$$\delta_{depth}=(a_{depth}-y)sigmoid’(z_{depth})$$
$$\delta_{n-1}=\delta_{n}\theta_{n-1}^Tsigmoid’(z_{n-1})$$
第六次作业 – SVM
- C参数作为正则项, 反应对误判的容忍程度
- sigma参数作为高斯核函数的参数, 反应两样本的相似性随距离变大收敛到0的速度.
垃圾邮件分类器
- 将邮件转换成index向量, (提前选出垃圾邮件中出现频率最高的一些单词)
- 然后将index向量转换成01单词出现向量.
- 对01向量进行SVM分类
注意计算核距离的时候
X2 = sum(X.^2, 2);
K = bsxfun(@plus, X2, bsxfun(@plus, X2', - 2 * (X * X')));
K = kernelFunction(1, 0) .^ K;
利用$$(x-y)^2=x^2+y^2-2xy$$
第七次作业 – K-means 和 PCA
K-means算法流程如下
% Initialize centroids centroids = kMeansInitCentroids(X, K); for iter = 1:iterations
% Cluster assignment step: Assign each data point to the % closest centroid. idx(i) corresponds to cˆ(i), the index % of the centroid assigned to example i idx = findClosestCentroids(X, centroids);
% Move centroid step: Compute means based on centroid % assignments centroids = computeMeans(X, idx, K);
end
事实上, 对所有的EM算法, 都是这个流程, 首先guess一个目标值, 然后进入循环, 计算中间值, 然后利用中间值计算目标值, 直到收敛.
需要注意的是, EM算法不一定能收敛到最优解, 所以一般同时计算多个初始值的结果, 利用(cost function找其中最好的一个, k-means用distortion)
一个实例 - 利用k-means进行图像压缩
对一个1281283的图像矩阵, 令每一个像素点为一个训练集, 为24位的特征数据, 训练成16个集合, 之后就可以用4位01来进行压缩表示, 最后只需要存储1281284+2416=65, 920, 而原来需要128128*24=393, 216bits, 大概压缩了6倍.

当然, 由于进行压缩后存储的是颜色索引, 所以需要进行图像还原后再显示.
PCA
PCA 可以用在其他算法训练前, 使得维度减少, 减小训练时间.
- 归一化
- 首先计算数据的协方差矩阵
- 计算特征值(svd, 一般)

协方差矩阵
$$\Sigma=\frac{1}{m}X^TX$$
[U, S, V] = svd(Sigma), where U will contain the principal components and S will contain a diagonal matrix.

实例 - 人脸图像压缩

可以看到主成分的脸
然后可以看到使用前100个分量计算后再进行恢复后的图像(基本上和原来的一致, 相当于对图像进行了压缩(我们关注能不能恢复))
optional - PCA用作可视化(多维数据映射到二维上进行可视化)
The PCA projection can be thought of as a rotation that selects the view that maximizes the spread of the data, which often corresponds to the “best” view


最后一次作业 - 异常检测系统和推荐系统
第一部分 - 检测异常系统
异常检测使用高斯模型建立, 对一个数据生成器对应的高斯模型, 然后依靠多维高斯模型的概率密度来对异常点进行检测, 这里有一个阈值问题, 所以采用有监督的方法寻找一个可靠的概率密度阈值, 之后可以求出这个阈值的F1分数
$$F_1=\frac{2precrec}{prec+rec}$$
其中$prec$是准确$rec$是召回
$$prec=\frac{tp}{tp+fp}$$
$$rec=\frac{tp}{tp+fn}$$
相当于一个优化问题, 找到最优的F对应的阈值$\epsilon$
第二部分 - 使用联合过滤建立一个电影推荐系统
通常而言, 我们只需要定义一个损失函数和其梯度, 之后利用优化方法就可以计算出最优的参数.
使用联合过滤相当于一个矩阵填充问题, 我们根据相关性填充一个未填满的矩阵来进行推荐.
需要注意的是联合过滤的参数是虚构的电影特征$X$和用户特征$\theta$
目标函数是
$$\frac{1}{2}\sum_{(i,j):r(i,j)=1}({\theta^j}^Tx^i-y^{i,j})^2$$
加上正则项则是
$$\frac{1}{2}\sum_{(i,j):r(i,j)=1}({\theta^j}^Tx^i-y^{i,j})^2+\frac{\lambda}{2}\sum_i\sum_j(X_{ij})^2+\frac{\lambda}{2}\sum_i\sum_j(\theta_{ij})^2$$
对X求导
$$\sum_{(i,j):r(i,j)=1}{\theta^j}^T({\theta^j}^Tx^i-y^{i,j})+\lambda\sum_ix^i$$